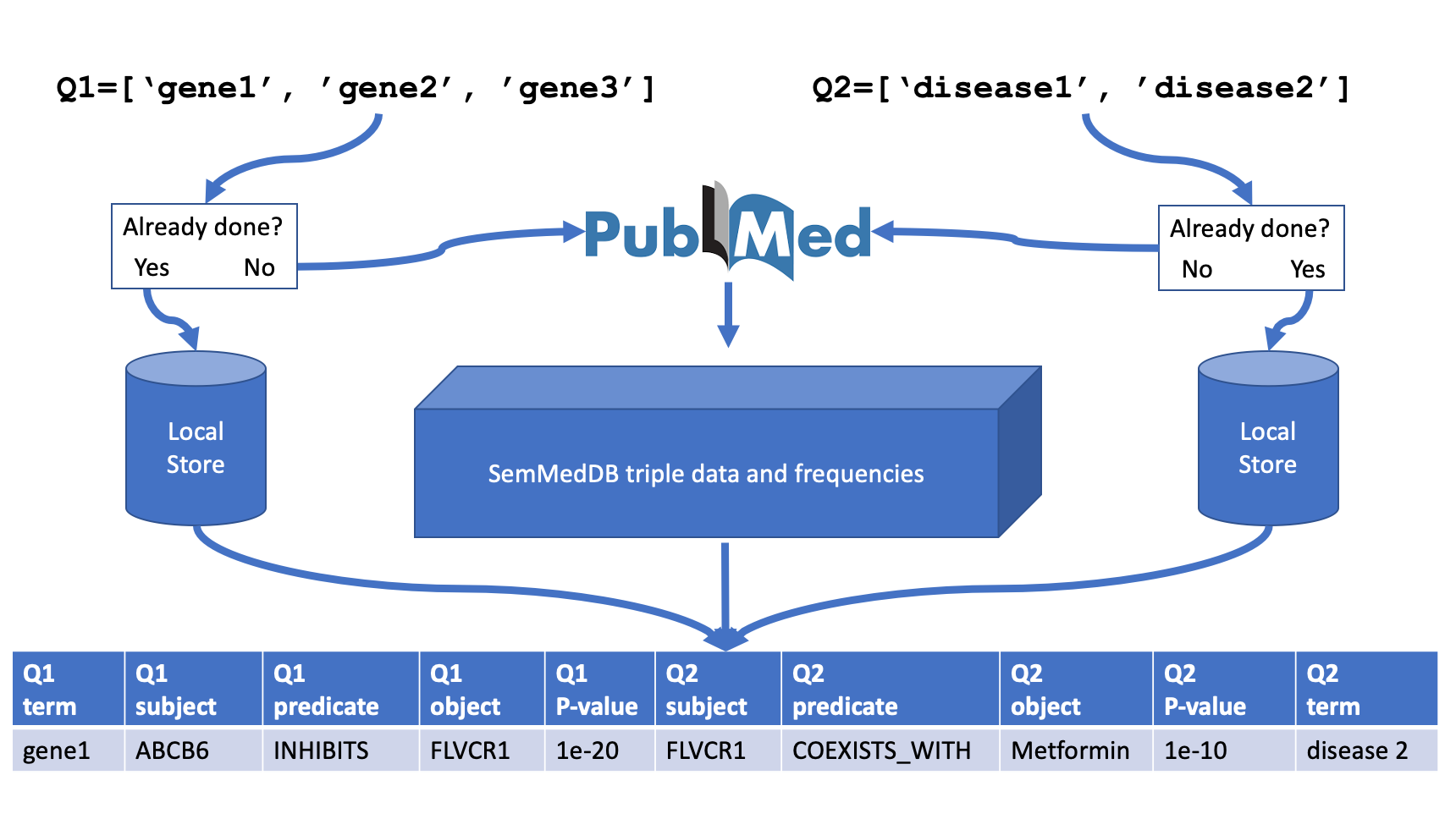
Previously we created MELODI, a method and tool to derive overlapping enriched literature elements connecting two biomedical terms.
Here, we present MELODI Presto. A quicker and more agile method to identify overlapping elements between any number of exposures and outcomes.